

Introduction and takeaways
In recent years, AI has become a reference point for today’s tech innovation. And it is expected to grow more in the next couple of years. From entertainment to the food industry and sports, AI is changing most of today’s enterprises, improving efficiency, products, and services.
But what about healthcare and medicine?
The collaboration between healthcare professionals and modern technology will carry a positive change and lead to a disruption in medicine, improving the outcomes and delivering better health services. And this is not a distant or utopian future, as we are gradually getting there, step by step.
But, the way to access data to build AI is not as easy as it is thought. It is important to keep in mind that ensuring privacy and patients’ data safety is one of the main goals that digital health companies should aim for.
To be able to access those sensitive data, there’s no magic formula available, but a mix of conditions and techniques will help you to mitigate the risk and, thus, access those data in an easier way.
Here are the main takeaways from this article:
✅ What you need to consider when developing AI in Digital Health.
✅ Types of health data use.
✅ Typical scenarios when using retrospective data.
✅ 5 key points to mitigate privacy and security risks.
Are you ready to jump into the AI world of data?
It’s a long way to the top: accessing data for AI in healthcare
Privacy can limit the amount of available data in healthcare. Sometimes, it seems like it is not possible to benefit from the AI advantages while keeping intact and safe patients’ data.
Well, unfortunately, there’s no magic formula to do so, but it is still possible to mitigate risks to accessing and elaborating those data. Let’s start with 5 key points:
- Legal basis: this is the main point that will drive you through the process. You need a proper legal basis in order to access, process, and use those raw, sensitive data. There are some exemptions to this, but we will go through them later in the article.
- Avoid extra-EU data transfer: today, using a US cloud provider is not the ideal solution. Alternatives such as edge-computing and federated learning are great alternatives that will help you to avoid extra data transfers.
- Technical considerations: pseudonymisation and anonymisation will play an important role in risk mitigation. Keep in mind that if you are responsible for the anonymisation, you will need to collect consent from the patients or provide a proper alternative legal basis. Anonymisation is still a processing activity, and you need to access the source of data in order to perform it.
- Scope: the larger the dataset, the better. If you are leading a clinical trial with a reduced amount of people involved, it will be harder for you to mitigate the risks. In fact, the possibility of re-identification is higher for a restricted group of people, even with anonymisation set up.
- National regulations: don’t forget to check your national regulation - each EU country can apply softer or stricter rules to the processing of sensitive data. The EU is working on a European framework to regulate AI, but we will go through it in a future blog post.
GDPR as the starting point
Although the GDPR harmonizes the rules governing the processing of sensitive data, there are still options for EU countries to specify justifications for processing health data in their own national law. Moreover, it provides that with regard to the processing of genetic, biometric, or health data, each State can maintain or introduce further conditions, including limitations.
Understanding the types of health data use
Before diving into the topic, let’s understand a little more about data usage.
The specific rules for collecting health data vary depending on the jurisdiction you operate in. For instance, in the EU, personal data can only be processed if you have a legal basis for doing so. For most cases, this basis would be the execution of a contract or informed consent. But with health data, you have to use an additional different basis.
The important thing is you will need to get a proper legal basis if you want to use this data.
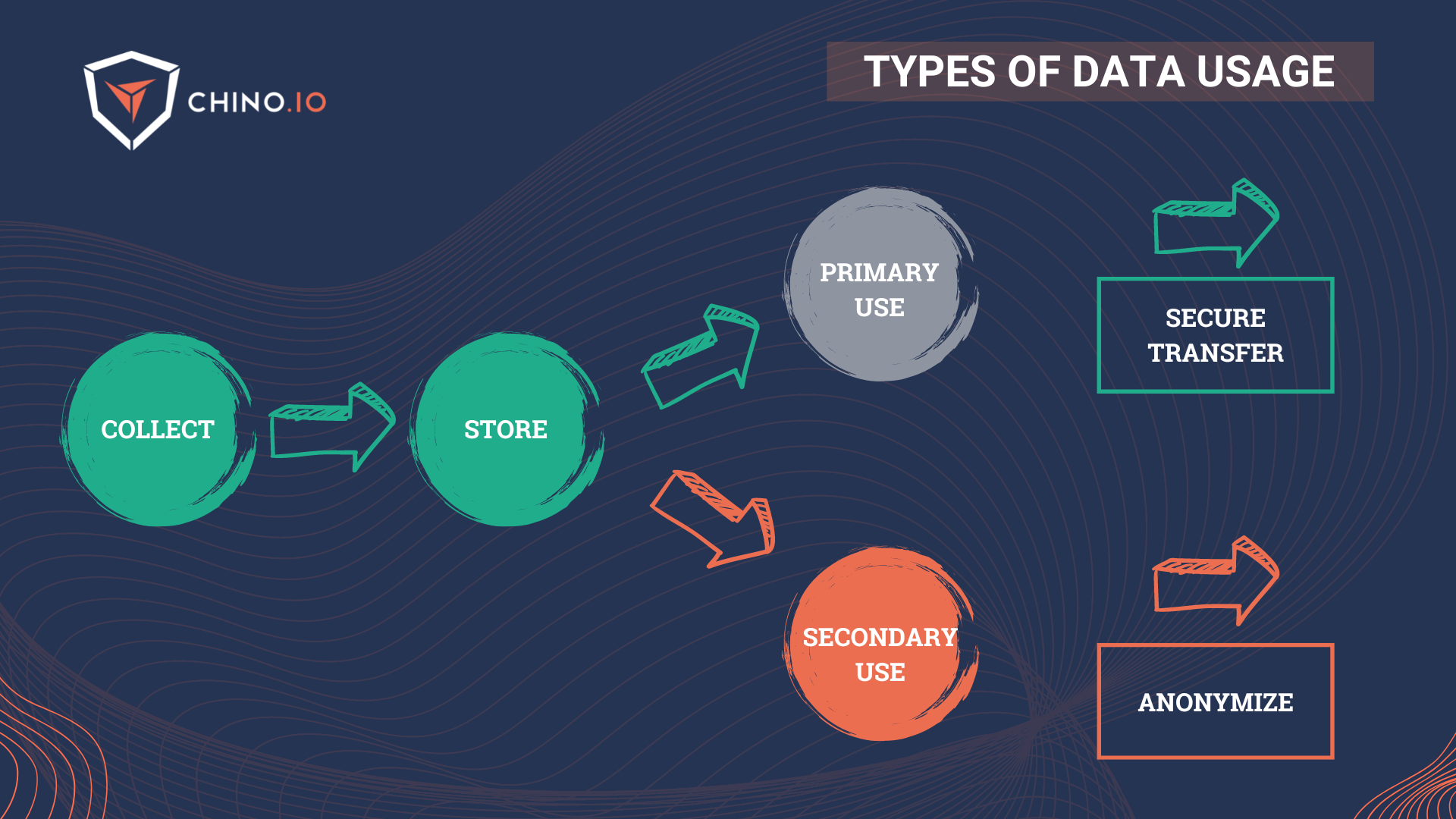
At this point, as you may probably know, there are two main uses for data in the healthcare environment (and not only) that go under the name of primary and secondary use:
🔎 Primary use: all the health data that are collected directly from a patient in the context of health and social care provision for the purpose of providing health or care services to that patient. This is mainly used for prospective data.
🔎 Secondary use: the possibility of re-use of health data that were collected initially in the context of providing care but which may later be re-used for another purpose. It may be exercised by public entities (including universities and public health laboratories for research purposes), regulators, med-tech companies, and small pharma.
Today, access to data in hospitals and clinics is still difficult due to several factors, among which we can highlight:
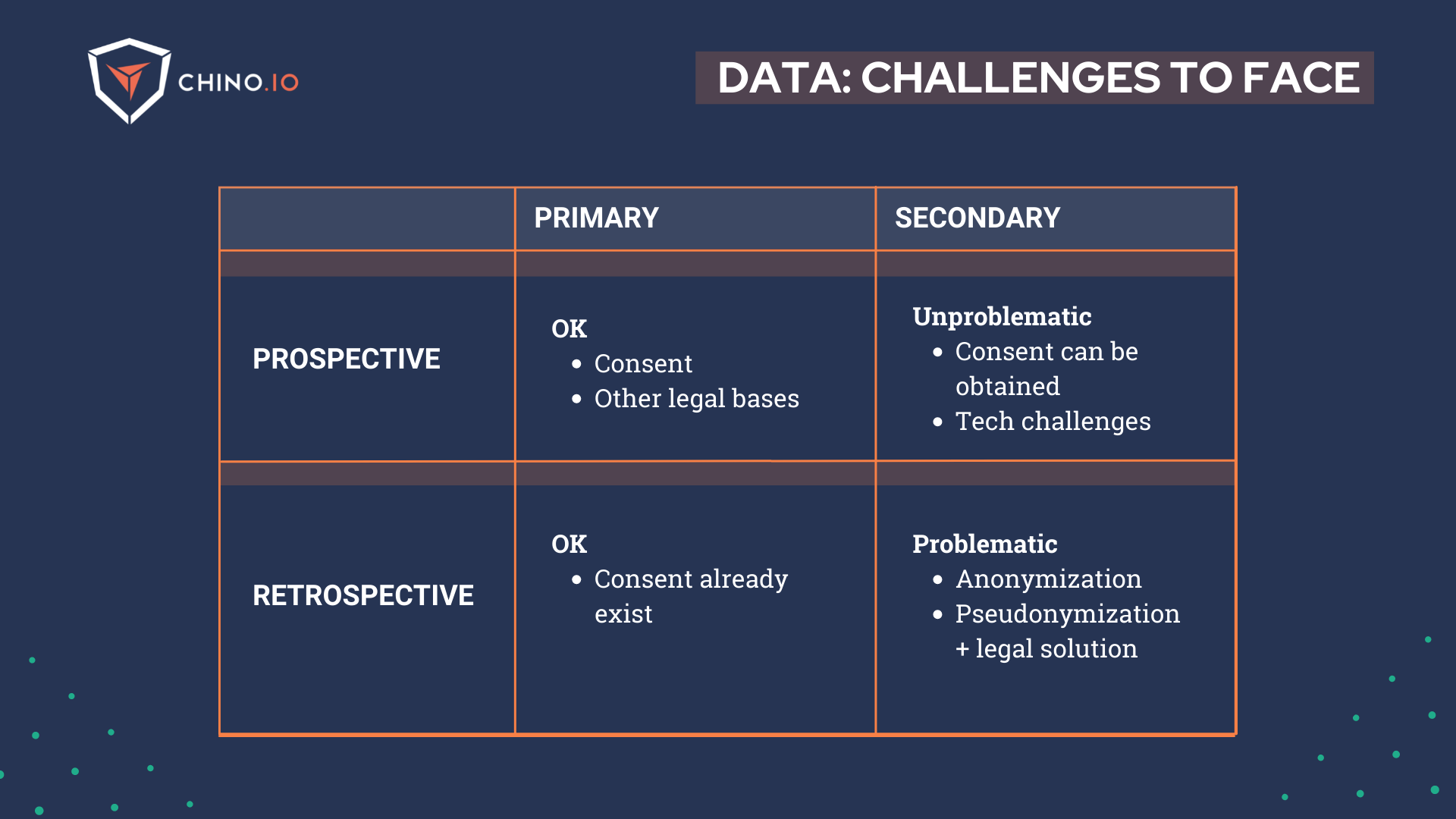
- The absence of legal bases: it is possible to use data only for primary intended purposes. Secondary use is not possible due to the absence of a previous proper privacy notice. In fact, personal information must be “collected for specified, explicit and legitimate purposes and not further processed in a way incompatible with those purposes.” This means that the purposes of data processing must be specified precisely - thus, further processing must be compatible with the purposes for which those data were originally collected.
- It is not always possible to anonymise data coming from hospitals and clinics: privacy laws in the EU are based on legal basis (if the data are anonymised, consent is not required). Anonymised data is no longer considered “personal health information” - for this reason, it allows the sharing of information when it’s not mandated or practical to obtain consent, for example.
- The impossibility of obtaining new consent from the patients: it is not always possible to ask for new consent as you can run into other practical problems, for example:
- The cost of contacting thousands of individuals in terms of time and financial effort needed;
- The effort needed in trying to reach patients after the health services when they may have relocated, died, or simply don’t want to give their consent after the experience.
Using retrospective data: 3 typical scenarios
At this point, we can list 3 typical scenarios when using retrospective data:
1️⃣ Consent-based data processing: When you have explicit consent, you should be fine. Keep in mind that consent applies for specific data processing purposes you outline in your consent request forms and privacy policy, and if these change, you may need to ask for consent again. The main challenge for this point is when you need to get consent and you don’t have contact with the subjects anymore.
2️⃣ Legal basis related to medical research: Depending on the purpose, type of research, and type of data you are going to analyse, there are alternative legal basis (instead of the consent) upon which you could rely on. There are research or medically related purposes, which are usually quite restrictive regarding what you can do. They are usually instrumented by the national laws of the country from which you obtain the data. If this is the strategy you move forward with, you have to take special care of making sure that the processing you are doing is in accordance with these laws and that all the project documentation is in line with it, particularly any sort of data processing agreement you have with the hospital/data controller.
3️⃣ “Curated” databases (aka Biobanks): There are preprocessed databases sold by 3rd parties that have already been anonymised, or have been prepared for research following local laws. Typically, they are nationwide databases ready for research. While these resources are tremendously valuable for research companies, it is not uncommon that a lot of the responsibility in the processing of this data is offloaded to you. Be careful with the contracts that you sign, and make sure that you abide by them when you actually process the data. While there are always risks of fines and similar, the most tangible risk in this scenario is that you can easily lose access to the database very easily. So, if you can’t get consent, search for a biobank - you won’t need to work with clinical partners to get those data.
Still not clear?
Working with sensitive patients’ data can be a tricky issue.
As we have seen, the issues related to privacy and access to data can seem hard to overcome, yet it is still possible to make it happen.
Recently, Chino.io got involved in AIccelerate, an H2020 project that aims to develop AI solutions provided by the Smart Hospital Care Pathway Engine for different types of healthcare uses. As partners of the project, we have faced from day 0 the obstacles of gathering both prospective and retrospective data from the hospitals involved in the project.
There’s no magic formula to get this done, yet, a mix of conditions can help you to mitigate the risk and, thus, get more chances to access the data you need.
And I want to share them with you.
Don’t forget that in all of these cases, you need to have a legal basis (either given by GDPR, or national laws based on risk minimization) put in place. Your goal is to ensure the data owner to let your company access those data. To do so, you will need to:
🔳 Show that you mitigate all risks that can arise throughout the process;
🔳 Demonstrate that you are able to lead the project, both on the technical and legal side;
🔳 Show you care for the users' data.
So, these are a combination of measures that could help you reduce risks and enable you to access data.
- Edge-computing: the connectivity paradigm that places processing as near as possible to the data source - with fewer activities performed on the clouds. Edge computing and AI are driving faster and more effective diagnosis and treatment plans, for example. Today, it is well known the problem of US cloud providers in Europe.
The pervasiveness of US cloud and tech providers is so high that transitioning to other providers or adding security measures can still require a great amount of effort needed to switch.
Here are some previous blog posts about the topic:
📌 Germany bans US cloud providers for digital health apps
📌 Beyond Google Analytics: What the Austrian DPA decision means to you
- Synthetic data: as EU regulations are making it difficult to process and utilize data (especially across organizational boundaries and even harder abroad), one solution is using data produced artificially and designed to avoid any potential connection with real-life patients. Practically, the dataset is built on “fake data.” - the use of Artificial Intelligence to create and simulate datasets that mimic the real world. This is a good alternative if you don’t have the opportunity to use real data (due to consent restrictions, for example) or if you don’t have enough real-world data.
- Anonymisation: data anonymisation involves completely removing all personal identifiers from the data making it impossible to trace the data back to the individual. The thing here is simple: the responsible for the anonymisation must have consent or a proper alternative legal basis from the patients in order to perform it. In fact, if you perform anonymisation, you will need to access the former source of data - and thus sensitive information such as demographic, pathologies, and other sensitive information. This won’t apply to you if you receive data already anonymised by an external partner.

- Specific advice from the DPO for research performed within health institutions that falls within existing legal basis related to research. DPOs, with their expertise, can provide you with precious advice and help you to solve and speed up the entire process.
Keep in mind that all the mentioned strategies need to be combined together in most cases to ensure security, compliance, and smooth project execution, and by no means do they replace legal basis!
Chino.io, your trusted compliance partner
Working with experts can reduce time-to-market and technical debt and ensure a clear roadmap you can showcase to partners and investors (see our latest case study with Embie).
At Chino.io, we have been combining our technological and legal expertise to help hundreds of companies like yours navigate through EU and US regulatory frameworks enabling successful launches and reimbursement approvals.
We offer tailored solutions to support you in meeting the GDPR, HIPAA, DVG, or DTAC mandated for listing your product as DTx.
Want to know how we can help you? Reach out to us and learn more.






