Privacy can limit the amount of available data in healthcare for medical research and the development of new products.
It seems that it is impossible to benefit from AI advantages while keeping patient data intact and safe.
To overcome this, several AI companies have found the answer to many problems in synthetic data: data sharing, algorithm training, and collaboration with third parties.
What is synthetic data, and how it works
In a nutshell, this is how it works: a company has a dataset that it wants to use for a secondary purpose.
Before using those data to train an AI algorithm, the data must undergo a specific treatment to be considered anonymous.
They turn to synthetic data, which basically consists of running an algorithm (or several) on the original dataset to create an altered copy that retains the statistical significance.
Prospective vs Retrospective
Before diving into synthetic data, let’s give an overview of the context (and challenges) around collecting data in healthcare.
We often hear about prospective and retrospective data (and the challenges that may arise).
Let’s see the difference between the two:
- Prospective: Data that are collected for a specific purpose and starting from a specific moment. For example, they are usually collected for a specific research project (that have not yet been collected or aren’t part of another project/study).
- Retrospective: data that has already been collected for another project or purpose.
In healthcare, when we try to use retrospective data, we are trying to perform what’s referred to as secondary uses of data (which we will see in the next chapter)
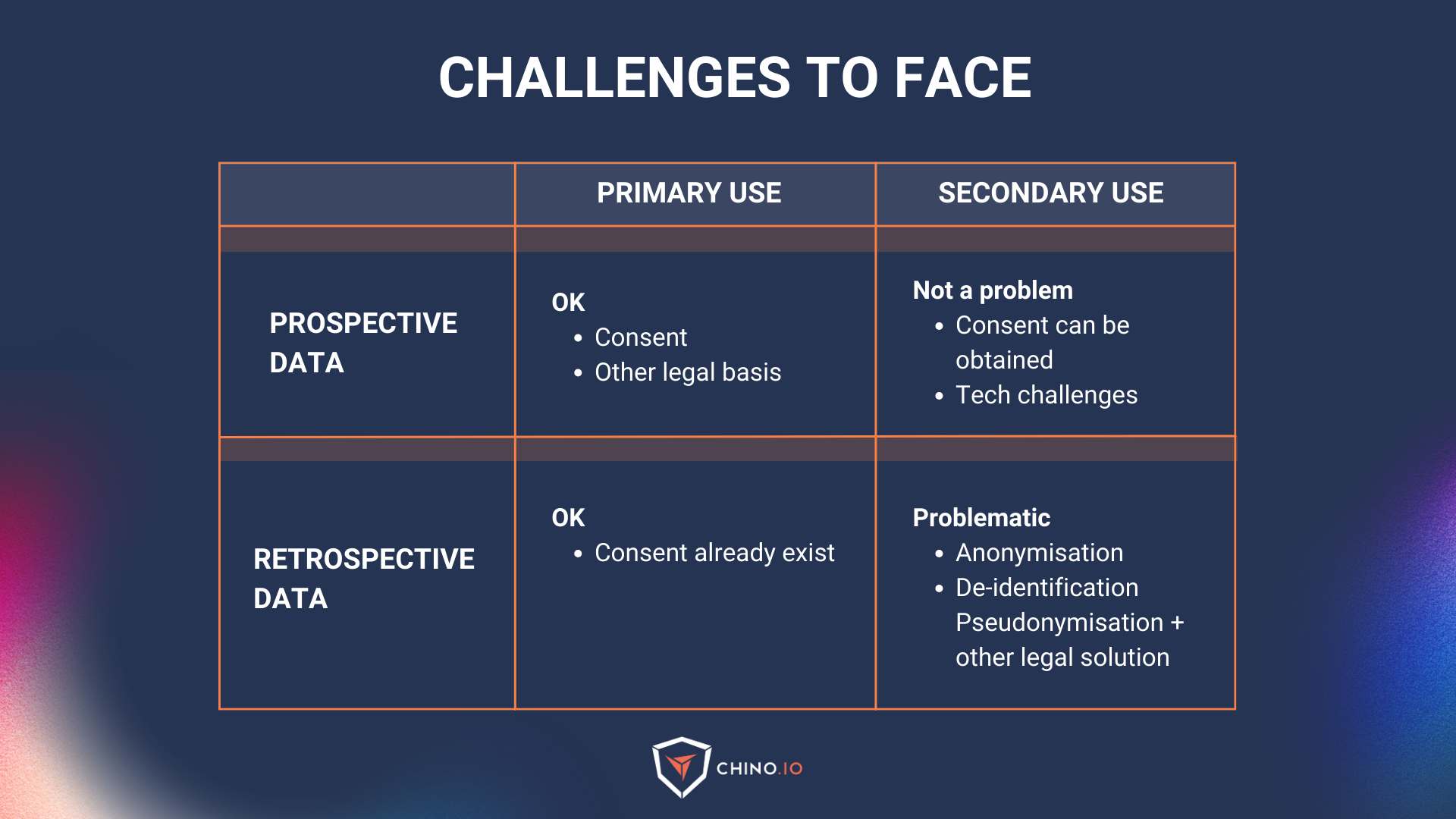
Primary vs. secondary use of data
In the EU, personal data can only be processed if you have a legal basis for doing so (e.g. executing a contract or informed consent). When establishing these legal bases, there is a purpose attached to it, which falls into one of two categories:
Primary use: all health data collected directly from a patient in the context of health and social care provision to provide health or care services to that patient. This is mainly used for prospective data.
Secondary use: the possibility of re-using health data collected initially in the context of providing care but which may later be re-used for another purpose. This is a sort of gold mine that everyone is searching for but it’s not that easy to access to it. It may be exercised by public entities (universities and public health laboratories for research purposes), regulators, med-tech companies, and pharma.
Using data for primary uses is relatively easy. Usually, it translates into a checkbox when the user signs up, or a contract (Data Processing Agreement) between two business partners.
However, secondary use is much trickier for a number of reasons:
- Usually, consent to this is optional (e.g. Google or Apple asking if they can get diagnostic data from your device, or track your usage for product improvement. You can refuse it, and they can’t make you pay more for the service if you use it).
- Consent has to be asked in advance (i.e. before conducting the processing), meaning you have to know what those secondary uses will be, at least broadly, before actually processing the data for those purposes - and you can’t ask for consent just in case. It has to be specific and with a reasonable data retention period (aka the period you store those data).
- Anonymisation is not the ultimate solution by itself, since you require consent to anonymise the data for these secondary uses too.
This is why companies face a struggle with data re-use - there is a gold mine of retrospective data but it can’t be used without the consent of the users (unless you have another legal basis). In many scenarios this is very hard to get (if not impossible).
on EU projects
Why synthetic data can be a solution
If done in the right way, synthetic data is not retraceable back to the original dataset. Thus, data subjects cannot be re-identified (pretty cool, right?)
And the benefits really come to light when companies decide to build and implement AI-based solutions.
Less tech challenges: Anonymisation is a real challenge for all tech companies. Not only is it really hard to achieve, but you also need to undergo an assessment to ensure your customers, partners, and stakeholders that you are doing it in the right way.
Here is the trick: you can skip the assessment phase if you are getting synthetic data from an external partner (who is responsible for the anonymisation). However, if you are creating your own synthetic dataset, you need to undergo the assessment (as you are responsible for anonymising the dataset you have).
Ethics and compliance: Bias is one of the most relevant concerns when it comes to AI. Synthetic data reduces this issue by creating unbiased data (and thus offering a more ethical approach during the development of the AI). This is a key aspect if you are collaborating with public institutions on EU projects.
Things you need to consider when using synthetic data
Unfortunately, synthetic data doesn't work in all cases:
- If you have sensitive data (that falls under Art 9 of the GDPR), you still need explicit consent from the data subjects BEFORE the anonymisation process—unless you have defined a different legal basis for the processing (e.g., post-market surveillance for medical device companies, scientific research).
- If you want to use data for collaboration with a third party in any way that would imply the re-identification of the subject at some point (e.g., financial fraud detection), this method is not suitable since you are technically unable to re-identify the subjects.
Are there cases where sensitive data is shared without prior consent based on scientific research (as outlined in Art. 9(j) of the GDPR)?
Yes, plenty. This is the basis for enabling data sharing in many Horizon projects in which we participate. In these cases, synthetic data can be a powerful tool to preserve individuals' privacy.
Just keep in mind: be careful when creating your own synthetic data dataset with sensitive data - you still need explicit consent from the data subject to do this!
Getting started with synthetic data (in a compliant way).
There are three main scenarios that come into mind when talking about synthetic data (with both pros and cons).
Scenario 1: Get a dataset using a biobank
Data from biobanks can be used in various research studies, including basic medical research, and clinical trials.
When dealing with a biobank, you are getting real data (precious for your AI algorithm).
However, before using those data, you need to anonymise the dataset most of the time.
🟢 Pro: These are real data from the real world. You don’t have any risk regarding the quality of the dataset.
🔴 Cons: In most cases, you are in charge of ensuring the compliance of the data you are using. This means you need to do homework using those data (carrying out a compliance assessment is a good starting point).
Scenario 2: Use synthetic datasets
Here, you are buying data that was already collected and anonymised by your service provider. This means that you don’t need consent to use those data and that you are not in charge of the anonymisation process.
However, before buying and using the dataset, make sure that the partner complies with national regulations and standards.
🟢 Pro: Synthetic datasets are already anonymous and guaranteed by the provider. Here, you are not in charge of the anonymisation process (and you can skip the compliance assessment).
🔴 Cons: These are not real-world data. This means that these datasets can lower the quality of your AI algorithm.
⚠️ General rule: Before buying or using a dataset coming from an external provider, make sure that the partner complies with national regulations and standards.
Scenario 3: Create your own synthetic dataset
Here you should think about synthetic data as an anonymisation technique.
So, first of all, you need to anonymise your dataset. This is tricky and requires you to work on different aspects (both legal and tech).
1️⃣ You need a proper legal basis: explicit consent or other different legal basis for the processing (e.g., post-market surveillance for medical device companies, scientific research).
2️⃣ I need to carry out an anonymisation assessment: the assessment will help you to demonstrate to your stakeholders and partners that you are a “black belt” in anonymisation.
3️⃣ Create your synthetic dataset: once you have all the baseline set up, you are ready to create your synthetic dataset. Remember to review the entire process once in a while and consider re-anonymisation if necessary.
🟢 Pro: You create synthetic data from a dataset that you know and validated. This is the best starting point as you have already assessed the quality of your data.
🔴 Cons: You need to implement all the points and measures usually required as if you were performing anonymisation. This means deep tech knowledge, a strong legal basis, and a great willingness to maintain the process update!
Overall, synthetic data is a great technical solution that can help companies like yours get better data for AI purposes.
From a technical point of view, it gives you a full dataset created from real data that you can use later (also when a user revokes consent).
On the contrary, all other anonymisation techniques will give you very partial data that may affect the performance of your algorithm.
I hope this helps to shed some light on the topic. If you are not familiar with the topic or not sure what to do, feel free to reach out!
Chino.io, your trusted compliance partner
Working with experts can reduce time-to-market and technical debt and ensure a clear roadmap you can showcase to partners and investors (see our latest case study with Embie).
At Chino.io, we have been combining our technological and legal expertise to help hundreds of companies like yours navigate through EU and US regulatory frameworks, enabling successful launches and reimbursement approvals.
We offer tailored solutions to help you meet the GDPR, HIPAA, DVG, or DTAC requirements for listing your product as DTx.
Want to know how we can help you? Reach out to us and learn more.