

The processing of personal and sensitive data is at the heart of many apps and digital services today.
As developers, we know that dealing with those types of data means a great effort in terms of legal and tech considerations but a competitive advantage if this happens.
If an app has at its core the collection of personal and sensitive information, it must be GDPR compliant to be used in the EU. This means that we should be aware of what type of data we are collecting, their journey, and where they can be inserted.
What happens when a user puts personal data in a free text field even though we tell them not to? How do we deal with this case?
Let’s go through it together!
What is personal data?
Let’s see some of the common words that we will be using throughout this scenario.
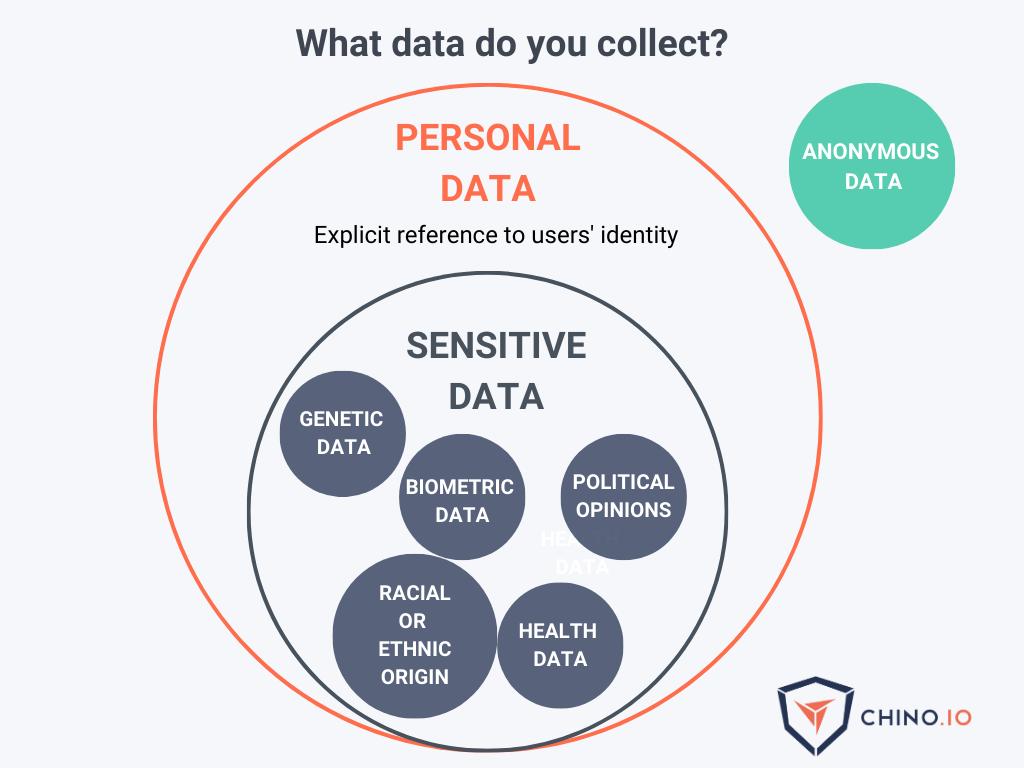
Personal data: any information that relates to a living individual. Personal data consists of unique identifiers. These are pieces of information, which, collected together, can lead to the identification of a particular person. Since the definition includes “any information,” one must assume that the term “personal data” should be interpreted broadly. Some examples are:
- Name and surname
- Email addresses
- Phone number
- SSN
- Pseudonymous data (more on this later)
Sensitive data: this is a particular type of personal data, subject to specific processing conditions.
- Racial or ethnic origin, political opinions, religious or philosophical beliefs;
- trade-union membership;
- genetic data, biometric data processed solely to identify a human being;
- health-related data;
- data concerning a person’s sex life or sexual orientation.
You would be surprised if you knew how often doctors and laboratories use the Social Security Number of a patient as their patient ID, even though the platform providers tell them explicitly not to do it.
If this is the case, what happens? This is what we call weak psudonymisation. To avoid it, you have to take measures to reduce these actions to what would be a misusage of your app.
How do we deal with this case?
Suppose we have a digital health app (stand-alone or paired with an external device). You made a huge effort not to collect or process any personal identifiers. However, the user (doctor, pharmacist, lab) is using your free text fields to put a very personal identifier from the end user/patient.
How to mitigate the risk here?
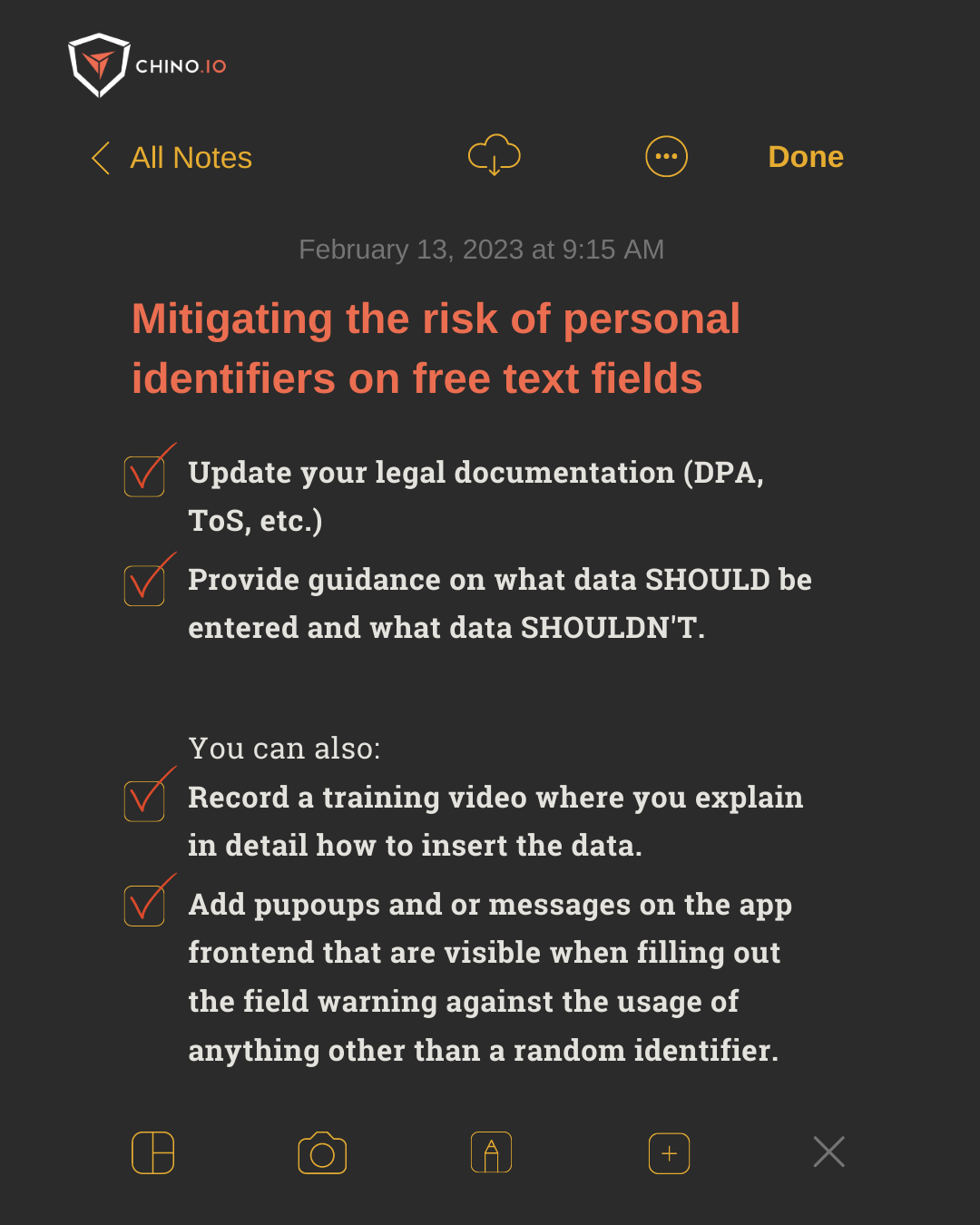
You have to explain throughout the app in a proper way what type of data they should enter and the ones they should avoid.
How can you do it?
📌 Writing in your legal documentation the data needed and where to put them
📌 Create guidelines (e.g., on the app documentation) on what data should be included and what data shouldn’t.
You can also:
📌 Record a training video where you explain in detail how to insert the data.
📌 Add popups or messages on the app front-end that are visible when filling out the field warning against the usage of anything other than a random identifier
Can you exempt yourself from the responsibility of this data once this is properly implemented?
If you put all the measures in place, you are ensuring privacy by design in your app. This is a great measure to implement pseudonymisation and reduce the risks of your data processing operations.
It doesn’t mean, however, that you are outside the scope of the GDPR. If you are processing pseudonymous data, you are still processing personal data under GDPR.
That’s not all, folks - remember that this data is very likely STILL personal data!
Whenever you are processing data that has individual data points from each user, this is most likely still personal data. Actually, this is most likely what we call pseudonymous data.
Pseudonymous data is still personal data under GDPR (both in the EU and the UK). This is because this data is potentially re-identifiable with other datasets available to others or companies (e.g., data that your users have, like the list of patient names associated with each random identifier they have on your platform).
https://blog.chino.io/what-is-pseudonymous-data-according-to-the-gdpr/
In particular, if you are processing any health, financial, or other sensitive data categories, you still have plenty of risks to mitigate.
So, while the steps above will help you mitigate risks and implement pseudonymisation as a technique, please don’t forget that you are very unlikely to be able to claim this is really anonymous data.
You still have to do all your GDPR homework.
BTW - if you are unsure about whether your dataset is truly anonymous, feel free to reach out to us. We will be happy to help you understand this with our free consultation.

What else could you do?
First of all, as a baseline of your data protection security strategy, you should be sure about implementing two types of measures: administrative and tech.
📋 From an administrative point of view, you must, among other things:
- Collect users' consent for data processing when applicable;
- Define and properly implement a Privacy Policy on your website or app, and make sure every detail about data acquisition modalities is set out in your Terms & Conditions;
- Process data lawfully and in compliance with the GDPR.
🧰 From a technical point of view, among other things you must:
- Enforce access controls (only authorised users can access the data);
- Store data in a safe place (e.g., use a hosting provider that guarantees compliance with GDPR);
- Ensure all partners with whom you share the data use it lawfully.
How Chino.io can help you
We are the one-stop shop for solving all digital privacy and security compliance aspects.
Successful compliance strategies evolve with you: for this reason, we have kickstart programs for startups developing their digital product. As a partner of our clients, we combine regulatory and technical expertise with a modular IT platform that allows digital applications to eliminate compliance risks and save costs and time.
Chino.io makes compliant-by-design happen faster, combining legal know-how and data security technology for innovators.
To learn more, contact us and book a free 30-minute call with our experts.




