

As a Digital Health Enterprise, one of your first concern should be how to protect the health sensitive data that you are collecting from your users and storing/managing in your service.
Encryption, pseudonymization and anonymization are some of the main techniques aimed at helping you on security of sensitive data, and ensure compliance both from an EU (with the General Data Protection Regulation - GDPR) and US (with the Health Insurance Portability and Accountability Act - HIPAA) regulations.
Take our free Compliance Self-Assessment to determine what are your privacy requirements based on data you are collecting.
Encryption
Let's start with the safest and most straightforward technique to secure the data. Encryption will make your data totally unintelligible to those who may try to access it, even in the case of data breaches.
Some problems with encryption
Although it's the safest technique, encrypted data cannot be searched and analysed before decrypted. Therefore, the main problem with encryption is that you need to find the balance between data security and usability because:
- You can't encrypt and decrypt everything when needed to perform search operations (although the new homomorphic encryption techniques will hopefully solve a lot of pains in the future).
- It is not always the easiest and safest choice to encrypt data by yourself. One reason is that you need to keep the encryption keys secure and protected. This is one of the most challenging aspects with encryption since losing the keys means losing the data.

Subscribe to Chino.io newsletter
Pseudonymization
As an alternative to encryption, there is pseudonymization, which allows you to remove personal identifiers from sensitive data so that the sensitive data contains only pseudo(false) identifiers. In other words it's a "false" anonymization because the data can be linked back to a person, but it's considered as a secure approach since personal identifiers are stored somewhere else.
As a matter of fact, data protection laws describe pseudonymization as a good security strategy. The GDPR defines it as:
[...] the processing of personal data in such a manner that the personal data can no longer
be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person. [1]
As you may notice from this definition, "de-identification" is a synonym of pseudonymization, since what is being called "additional information" (the personal identifier") is kept in a separate location, "subject to technical and organizational measures" suitable to keep it secure.
However pseudonymized data are still considered as “sensitive data” from a legal point of view, so you still have all legal obligations. However, it's by implementing pseudonymization you applied already a good security strategy. Furthermore, don't forget that:
Pseudonymisation is not a method of anonymisation. Trough anonymisation data are processed in such a way that they can no longer be used to identify a natural person. So, the process of anonymisation is irreversible.
Example
"Blood pressure" data and "surname" data would only be considered as "raw health data" and "personal data" if taken individually. However, if coupled, they do constitute "sensitive data", since the patient can be correctly identified. In this case "the surname" is the "identifier" which is going to be pseudonymised and kept secure in order to de-identify the raw health data.
The Ultimate Guide on GDPR and HIPAA compliance
Anonymization
Just briefly, anonymization is a process of removing all identifiers in a not remediable way. That means that there is even no single "pseudo id" associated with data that links back to a person. There must be nothing, 0 information that links back a data to a person.
For that reason, anonymous data are usually useful only for statistical purposes. And since here we are talking about health apps, and how to secure them, then we will leave this topic to other official resources like the EU Article 29 working party summary on anonymization techniques.
How Chino.io helps developers
Short answer: it helps on both encryption and pseudonymization!
...on Encryption
Chino.io encrypts data immediately after receiving them by using state-of-the-art encryption mechanism (e.g. AES-256). Data are never stored unencrypted.
Encryption keys and encrypted records are stored on different servers according to security best practices and standards.
Search operations are performed over encrypted indexes, ensuring fast responses and at the same time security.
...on Pseudonymization
As an app developer, the easiest way to achieve Pseudonymization would be to store part of the data on Chino.io, in a way that you can decouple sensitive and identifiable information in order to increase the overall security. This can happen in two ways:
1st Option to achieve pseudonymization: store sensitive data on Chino.io. Following this approach, our customers store only personal on their servers.
2nd Option to achieve pseudonymization: store personally identifiers on Chino.io. Following this approach our customer's delegate to us the management of personally identifiable information while they still keep pseudo-anonymized sensitive data on their servers. This is the case when sensitive data are numerical values that need to be processed by some algorithms, and storing them on Chino.io API is not practical.
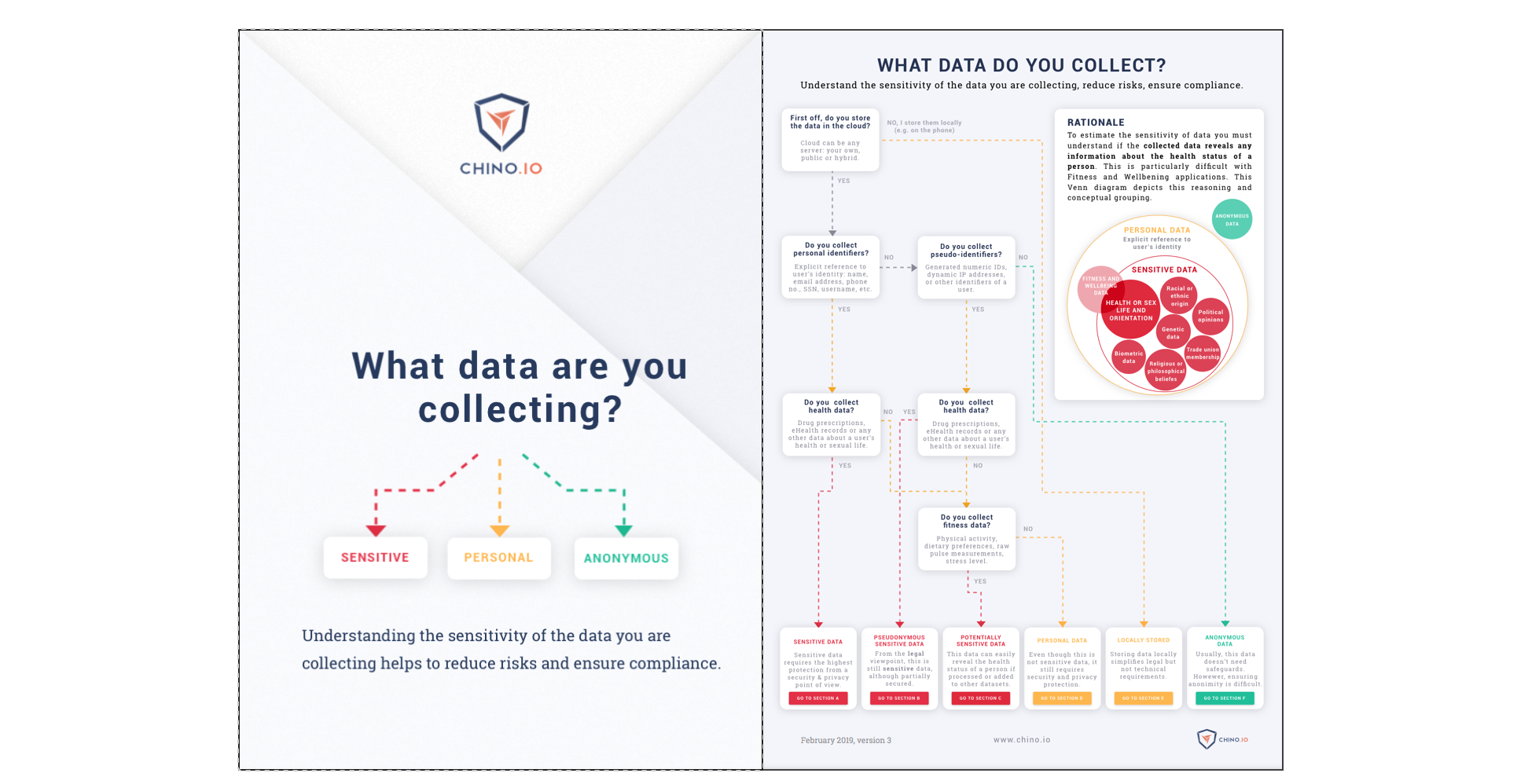
Download Chino.io Guide to Health Data Categories
photo credit to makyzz @ Freepik
See art. 4[5] GDPR. See also recitals 26, 28, 29. ↩︎



