

During my work, I often come across myths relating to GDPR. Here, I dispel the five most common GDPR myths about digital health.
I have spent many years now focussing on data protection for digital health. Long before the GDPR, I was working on systems to allow people to safely share their health data. Now, as CEO of Chino.io, I spend most of my time advising digital health companies on how to be GDPR compliant. However, time and again, I come across the same misconceptions and myths about what GDPR means for digital health. In this article, I want to confront five of these GDPR myths head-on.
GDPR Myth 1: GDPR doesn’t apply because we anonymise the data using random identifiers
I lost count of how often I heard people say, “I don’t need to do GDPR because I use random identifiers to anonymise my data.” People mistakenly believe that pseudonymisation and anonymisation are equivalent. Pseudonymisation is the process of replacing personal details with random IDs. Anonymisation is the process of ensuring data can no longer be associated with a specific individual, as shown below. The GDPR makes it clear that anonymous data isn’t in scope.

The problem is many people assume that if they pseudonymise their data, the data is already anonymous. However, pseudonymous data is definitely still personal data. The following diagram shows how pseudonymisation works.
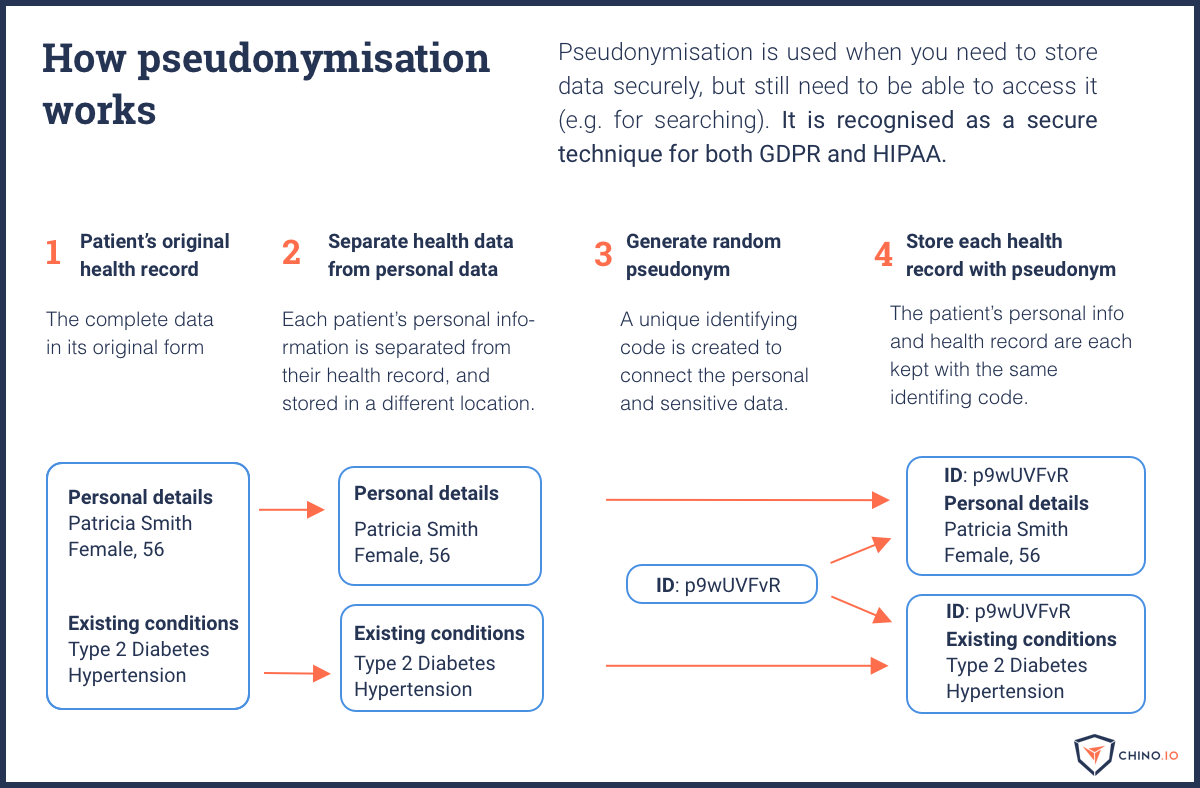
Even if you are anonymising data, you need to be aware of some potential issues. Firstly, data is only truly anonymous if you can be sure the original data subjects can’t be re-identified. This generally means you have to combine data from multiple users, add noise, generalise the data, etc. This is infeasible for any app that needs to link data with a specific user, hence the need for pseudonymisation.
Anonymising health data like scans is especially hard because they often contain biometric data.
Fact 1: Under GDPR, pseudonymous data is still personal data. However, pseudonymisation is a key step you should take to protect sensitive data.
GDPR Myth 2: I always need to ask for consent/consent is always the basis for processing
A lot of people believe that the only way you can process data under GDPR is if you ask the user for consent. However, there is a long list of things that count as a lawful basis for processing data.
(a) Consent: the individual has explicitly given you consent for you to process their personal data for a specified purpose.
(b) Contract: If you have a contract with a person, this may include elements that make it necessary to process their data.
(c) Legal obligation: Sometimes, you have a legal obligation to process a person’s data beyond any contractual obligation.
(d) Vital interests: You are always allowed to process the data if it is necessary to protect someone’s life.
(e) Public task: Public bodies often have obligations to process data in the public interest or because there is a clear legal basis to do this. For instance, Public Health Authorities can collect data relating to public health risks.
(f) Legitimate interests: This is the least clear basis for processing. Often, you can claim that you (or a third party) have a legitimate interest in processing the data. For instance, this allows salespeople to contact people without explicit consent. However, you have to check that there is no reason to override these legitimate interests.
Fact 2: There are actually many different legal reasons for processing personal data
GDPR Myth 3: GDPR means that I can only use the health data for my app
Lots of people believe that health data can only be used for digital health apps. However, the truth is you can do anything with the data, so long as you have a legal basis to do so.
For instance. For instance, it’s often perfectly acceptable to have a secondary use for your data, such as using it for internal research. You can even share the data with third parties. What I would say is deciding what you can do with the data isn’t black and white. I always recommend that people speak to a lawyer with expertise in this field.

Fact 3: Health data can be used for many purposes, but only if you are completely compliant with GDPR.
GDPR Myth 4: I use AWS/Azure/Cloud XYZ, so my app is already compliant
GDPR requires you to meet a number of organisational and technical measures. In addition, you must demonstrate that you comply with the 8 data subject rights laid out in Chapter III.
Organisational measures refer to things like your privacy policy, internal policies relating to data protection, data processing agreements (privacy contracts) with your providers, etc. Technical measures are broadly split into logical security controls and physical security controls. In general, most cloud providers operate a shared responsibility model. Under this model, they are responsible for physical security controls, such as preventing unauthorised server access. However, you are responsible for the majority of the logical security controls.
The three main logical security controls for GDPR are encryption, pseudonymisation, and data partitioning. The default encryption used in most cloud setups is fine for personal data. But health data is defined as a special category of data under Article 9 of the GDPR. That means you really should use record-level encryption.
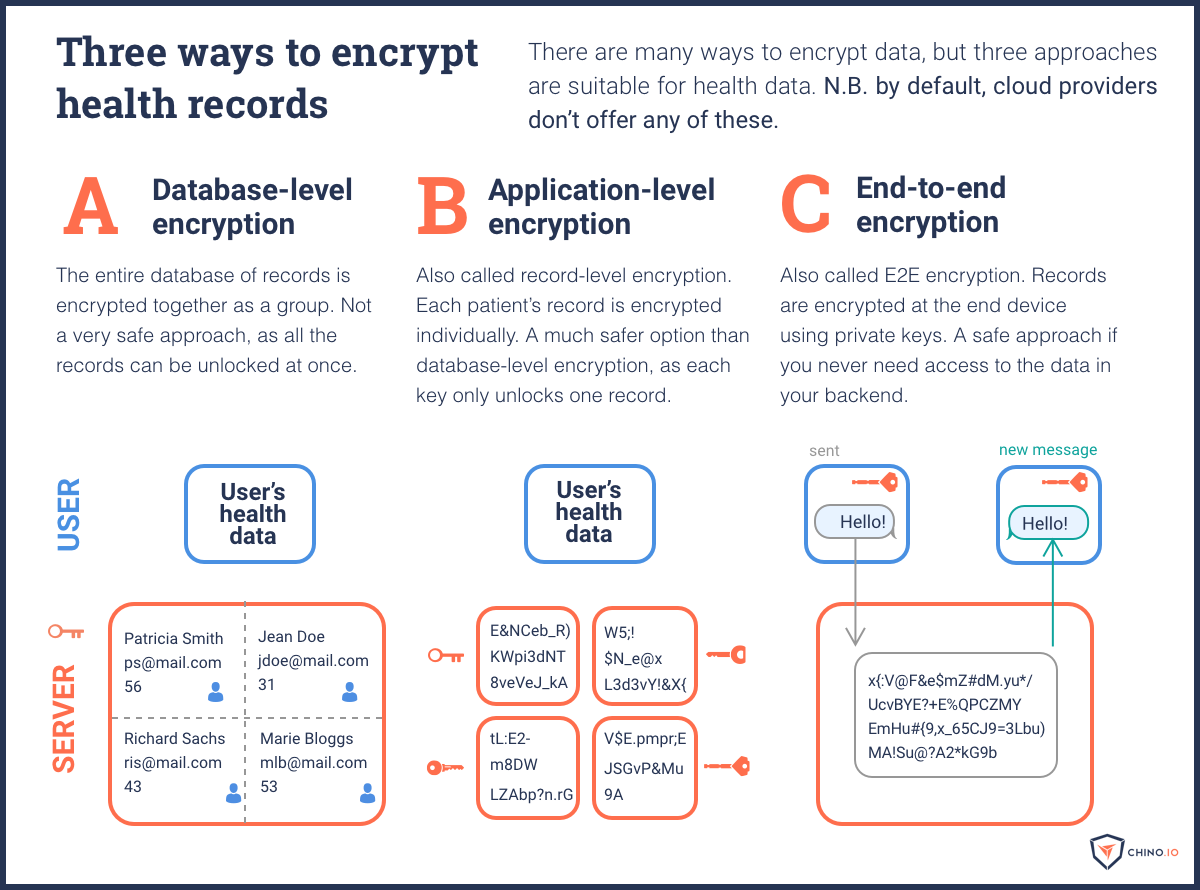
Partitioning is a way to make pseudonymisation even more secure. To pseudonymise and partition data, you start by splitting your records into two parts. The first part is the health data, and the second part is the personal data. You then create a pseudonym to allow you to associate both parts of the data. Finally, you store all three of these tables in separate locations. Ideally, that means on different instances or even separate clusters.
Fact 4: You need to apply numerous security controls when you are storing sensitive data, including record-level encryption, pseudonymisation and partitioning.
GDPR Myth 5: GDPR only applies to EU companies working in the EU
The final misconception I want to address relates to the territorial scope of GDPR. When GDPR came into force in 2018, there was a lot of confusion. GDPR primarily exists to protect people residing in the EU. However, controversially, it also imposes requirements on companies based outside the EU that process the data of an EU citizen. So, what does that actually mean? Well, let’s look at a couple of examples.
- You provide services to users within the EU but are based outside the EU. Here, you always have to be GDPR compliant. There are also quite complex rules you have to meet in order to be fully compliant.
- You operate a digital health app for people in the USA. However, this app is available to anyone that downloads it. In this case, you could well end up falling under GDPR unless you can be certain no one in the EU is using your app.
- You are based in the EU but solely handle data of non-EU citizens. Here, you have to be compliant with the GDPR because you are based in the EU.
At the end of the day, it pays to check the details with an expert.
Fact 5: GDPR always applies if you or any of your users are in the EU. However, it may also apply in other circumstances too.
Conclusions
I hope this article has helped dispel some of the myths and misconceptions that abound about GDPR. Of course, this list is far from exhaustive. At the end of the day, if you want to be sure you are compliant you should check with a real expert.





